
MASTERING YAML SYNTAX
.
8 minutes
INTRODUCTION
Before you can master YAML SYNTAX, lets discuss the introduction of Configuration Management and configuration management tools, provisioning and managing hardware were done manually, which was time consuming and required a lot of effort. The introduction of configuration management and its tools have made it easier to monitor and track changes made to multiple systems, allocate resources and a lot more. There are numerous tools used for configuration management but this guide focuses on Ansible, and how it can be used to automate and manage tasks.
WHAT IS CONFIGURATION MANAGEMENT?
Configuration Management is the process of maintaining, managing systems, and automating administrative tasks such as: package installations, configuration and reconfiguration of systems, tracking and documenting changes made to systems, system and software updates . These systems could be anything from servers, applications, to network devices and other IT components. Configuration management is often used in cases where you have to manage multiple servers or systems.
When making updates to a couple of systems or installing packages, it is easy to just do it manually since you have to repeat the code or process only a few times. But it becomes cumbersome when the number of servers increases. Say you have ten to twenty more of those servers to configure, you have to log into each system and repeat the same process as before. The task gets daunting and frustrating quickly and you are likely going to make mistakes along the way. Maybe you skipped a step or you repeated a step for the same server. Writing down the process to avoid mistakes is a logical way to go about it, but you still have to repeat the same process multiple times for whatever number of servers or systems you have to perform the task on. This is where configuration management comes in.
WHY IS CONFIGURATION MANAGEMENT IMPORTANT?
Configuration Management takes off the burden of repetitive tasks by simply automating the process for you and helping you track the changes you’ve made to each system. This gives you more time to be more productive and focus on other tasks. Another benefit of configuration management is that it keeps systems consistent and in a desired state while using minimal resources. It ensures that machines and packages are up to date and rightly configured. Configuration Management helps engineering teams build robust and stable systems by simply using tools to manage and monitor updates made to configuration data, which also reduces the risk of system disruption caused when changes are made to a system.
WHAT ARE CONFIGURATION MANAGEMENT TOOLS?
Earlier, we talked about how engineering teams make use of tools to build robust and stable systems. Configuration management tools are IT automation frameworks or software solutions that automate, manage, and set up configuration maintenance of software systems and processes. These tools enable faster, repeatable and scalable deployments and changes. They ensure that systems maintain a desired state. Each framework uses a series of configuration data files often written in human and machine-readable languages (YAML or XML), which are based on other languages. A good example is python(Ansible and Salt) or Ruby(Chef). Configuration Management tools have a workflow similar to ad-hoc shell scripts, but they offer a more structured and refined experience.
Some popular Configuration Management tools include;
Ansible Saltstack Chef Puppet CFEngine Although most configuration management tools support Linux, Windows, Unix, and mixed-platform environments, this article only focuses on Ansible as it is considered the most popular configuration management tool by many developers.
WHAT IS ANSIBLE?
Ansible is an open-source automation software application from Red Hat based on python. It can configure systems, deploy software and orchestrate advanced workflows to support application deployment, and system updates. Ansible as a configuration management tool is a popular choice amongst DevOps teams and system administrators due to many factors. Some key factors that put ansible at the top are;
Ease of Use: Ansible uses a simple human and machine-readable syntax(YAML) for defining tasks, and is also appropriate for managing any environment irrespective of the workload. This makes it accessible to a wide range of users. The simplicity of this syntax makes it easy to adopt for development of automation scripts.
Ansible is agentless: This means that you do not need to install any software on the target machine to work with ansible. This simplifies the setup and reduces the maintenance associated with managing agents on a large number of systems.
Security: Ansible makes use of OpenSSH , an open-source tool used for secure system administration, file transfer, and remote login, which ensures the communication between the host and target machine is secure.
Scalability: Ansible makes it easier to manage multiple systems efficiently, and it can be used for both small-scale and large-scale automation tasks.
Integration: Ansible integrates easily with other tools such as version control systems, continuous integration and continuous deployment (CI/CD) pipelines , and monitoring solutions.
Orchestration: Ansible also offers orchestration capabilities by helping users define workflows, and coordinate multiple tasks across multiple systems, making it suitable for complex automation processes. Ansible is decentralized: Ansible can easily control systems with just the help of your operating system’s credentials.
HOW DOES ANSIBLE REALLY WORK?
When working with ansible, there are two important nodes or systems to keep in mind.
The control or master node: The control node is the system in which ansible is installed and run on. As the name implies, the control node controls and runs the tasks on the managed nodes by using programs called the Ansible modules.
The managed or target node: These are simply the systems controlled or managed by ansible, the managed nodes could be servers, virtual machines, physical devices, or any software instances. they do not require any software installation for ansible to work.
ANSIBLE MODULES
Ansible modules are units of code or small programs that control the system resources or execute commands on your system. These modules do the actual work, they get sent from the control node to the target nodes, and they are removed when they are done. Ansible modules are very specific, you will find modules for everything, creating a file, copying a file, creating an instance, or even installing or restarting a web server. When writing a complex configuration, you will make use of multiple modules.
ANSIBLE PLUGINS
These are units of code that enhance the functionality of ansible. There are a number of playbooks used for various tasks, some of which include, action plugins, for executing actions required by playbook tasks, and callback plugins for adding new functionalities to ansible when responding to events. You can see more plugins here.
ANSIBLE INVENTORY FILE
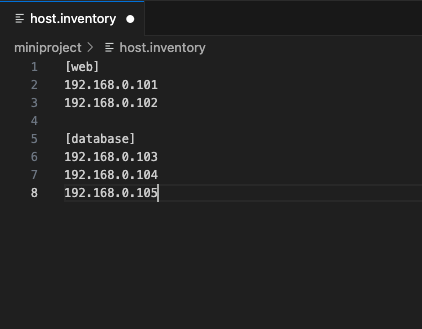
An inventory file organizes the managed or target nodes. Like an actual inventory, all the machines involved in the task execution are listed in an organized manner. The inventory file is created on the control node which gives ansible all the system information and locations it needs to help manage a large number of hosts with a single command. The hosts can be defined using their IP addresses or hostname. Multiple hosts are declared under a host group name using a square bracket.
ANSIBLE PLAYBOOK
Red Hat defines playbooks as a list of tasks that automatically execute on a specified inventory or group of hosts. Playbooks describe how, in which order, where, and when on the target machine the modules are to be executed. One or more ansible tasks are combined to form a play, and multiple plays in a file make up a playbook. Learn how to write your first playbook with Ansible interactive labs.
---
- name: Install apache2
hosts: web server
tasks:
name: Update package cache
become: yes
apt:
update_cache: yes
name: Install apache
become: yes
apt:
name: apache2
state: present
name: start apache service
become: yes
service:
name: apache2
state: started
enabled: yes
ANSIBLE.CFG FILE
The ansible.cfg file is a configuration file located under the /etc/ansible/ansible.cfg directory. It contains the configuration settings to modify ansible command-line tools, and controls how ansible interacts with your infrastructure. You can modify the ansible.cfg file to satisfy your environment’s use case. Some of the settings you can also configure in the ansible.cfg file include; inventory file, remote user, SSH settings. You can set up ansible on your control node with this guide.
###WHAT IS YAML?
YAML is an acronym that stands for Yet Another Markup Language or Yaml Ain’t Markup Language. It is a human-readable data serialization language mostly used for writing configuration files. YAML was initially created to be a superset of JSON. However, Yaml was designed to be more user-friendly and readable than JSON. It was created with the intention of making configuration data, data storage, and data exchange more accessible to humans. YAML is used to represent data structures, and scalar values in a human readable format. The latter acronym reflects the idea that YAML is not a traditional markup language like XML OR HTML, which uses tags to define data structures. In YAML, indentation and colons are used to define data structures, which makes YAML more user-friendly and readable to humans and it can be used with other programming languages.
YAML SYNTAX
YAML extension
YAML files use a .yml or .yaml file extension. Using this extension indicates that the file contains yaml-formatted data. The .yml and .yaml can be used interchangeably to represent yaml files. Both extensions are recognised by yaml parsers. We can identify yaml documents by their extensions. For example; playbook.yaml, settings.yml.
YAML document markers
The three dashes (---) that begin a yaml document are the document markers. They indicate the start of a yaml file and they are also used to separate multiple documents in the same file. To indicate the end of a yaml file, three dots (...) called, document end marker is used. The document end marker is often omitted for single yaml files because it is not necessary to use them except in the case of multiple documents to emphasize the end of one document before the other begins.
---
- name: months of the year
months:
month 1: January
month 2: February
month 3: March
month 4: April
month 5: May
...
---
- name: High level programs
programs:
program 1: Python
program 2: Ruby
program 3: Javascript
Comments Comments in yaml begin with a pound sign (#). They are used to provide explanations to lines of code or context for the data. Yaml does not consider comments as a part of the data it has to process.
# This document discusses the different months in a year.
---
- name: months of the year
months:
month 1: January
month 2: February
month 3: March
month 4: April
month 5: May
...
# This is the beginning of a new document in the same file
---
- name: High level programs
programs:
program 1: Python
program 2: Ruby
program 3: Javascript
Indentation
Indentation is used to structure yaml documents. It indicates the hierarchy of data and defines the nested levels of data. Tabs are treated differently in yaml as they can impact how a yaml document is parsed and interpreted. Spaces are recommended as best practice to use spaces in place of tabs for indentation. A common convention is to use 2 or 4 spaces for each level of indentation.
Key-Value pairs
key-value pairs are a fundamental way to represent data in yaml syntax. The key-value pair like the name implies consists of a key and a value separated with a colon (:). The key is typically a string and the value is represented with any data type. (strings, integers, floating points, boolean, arrays, dictionaries), a list (a sequence of values), or a map (nested key-value pairs).
# A string key-value pair
name: jane doe
# A key-value pair with an integer
age: 20
# A key-value pair with a boolean
female: true
# A key-value pair with nested mapping
contact:
address: N0 6, Purple Boulevard
hair color: Black
# A key-value pair with lists
favorite fruits:
Orange
Apples
Pineapples
Data Types
Yaml supports all kinds of data types which include Scalers, Mappings and Sequences Scalers: These include data types such as strings, integers, floats, booleans and Null. There are five styles of scalers in yaml syntax. (plain, double quoted, single quoted, folded, and literal) “` name: Jane # string Data type Age: 30 # Integer Data type Floats: 30.50 # Floating points Data type Boolean: true/false # Boolean Data type color: Null# Null Data type</p> <pre><code>Mappings: These include data types such as dictionaries or objects. They are denoted with key-value pairs and indentation to indicate nesting. </code></pre> <p>Example of a dictionary in Yaml contact: address: N0 6, Purple Boulevard hair color: Black</p> <pre><code> Sequences: They include data types such as lists. Lists are denoted using the hyphen(-) and indentation. “` # Examples of lists in Yaml programs: – program 1: Python – program 2: Ruby – program 3: Javascript
TROUBLESHOOTING YAML SYNTAX
There are numerous errors that you can encounter when running your configuration files. Navigating these errors can be challenging. Some of the errors you can encounter include; Indentation error Key-value pair formatting Merge errors Number type errors. By paying attention to errors and debugging them, navigating and ensuring your document is well structured and properly formatted becomes easier. You can find additional tips for troubleshooting yaml syntax in this guide.
Leave a Reply